Next: Data Plotting
Up: Sorting
Previous: PCA based sorting
Last step of the unit sorting is the clustering of the data.
NEV2lkit uses KlustaKwik, a program for unsupervised classification
of multidimensional continuous data. KlustaKwik delivers among others:
fit a mixture of Gaussians with unconstrained covariance matrices,
chooses automatically the number of mixture components, and runs fast
on large data sets. KlustaKwik is based on the classification expectation
maximization algorithm of Celeux and Govaert [CEM].
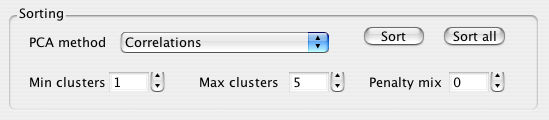
Definable parameters for the clustering process
in the NEV2lkit GUI are:
- [MINCLUSTERS] the random initial assignment
will have no less than n clusters. The final number may be
different, since clusters can be split or deleted during the course
of the algorithm. The default value is 1.
- [MAXCLUSTERS] defines the maximum of possible
clusters n. Cluster splitting can produce no more than n
clusters. The default value is 5.
- [PENALTYMIX] it is possible to specify Bayesian
information content (BIC) or Akaike information content (AIC) as the
penalty for a larger number of clusters or a mixture of these two.
This widget allows to define the amount of BIC to use a penalty for
more clusters. Default of 0 sets to use all AIC. Use 10 to use all
BIC (this generally produces fewer clusters).
All other parameters which are known in the standalone version
of KlustaKwik program can be edited in the source code of NEV2lkit.
Part of the NEV2lkit Documentation - 2004©M.Bongard, D.Micol 25.09.2004